The problems in this worksheet are taken from past exams in similar
classes. Work on them on paper, since the exams you
take in this course will also be on paper.
Problem 1
Jingrui finds a messy text file containing room availability and
pricing information at her favorite local hotel, the Manchester Grand
Hyatt.
Problem 1.1
Availability strings are formatted like so:
avail = """Standard: Available, This23: Available,
Suite: Available, Economy: Not Available,
Rooms are Available, Deluxe: Available"""
Fill in the blank below so that exp1 is a regular
expression such that if s is an availability string in the
format above, re.findall(exp1, s) will return a list of all
of the available room categories in s. Example behavior is
given below.
Note that your answer needs to work on other availability strings;
you should not hard-code "Standard", "Suite",
or "Deluxe".
exp1 = r"_____________"
Answer:([A-Za-z]+): Available
In the above availability strings, we’re looking for a
one-or-more-length sequence of letters (not numbers, as mentioned in the
problem), followed by a colon and the word “Available.” However, since
we only want to return the room type, and not the colon or the word
“Available,” we use a capturing group (the parentheses) to just return
the word before the colon.
Problem 1.2
Consider the string prices, defined below.
one ="Standard room: $120, $2.Deluxe room: $200.75" two ="Other: 402.99, Suite: $350.25" prices = one +", "+ two
What does re.findall(r"\$\d+\.\d{2}$", prices) evaluate
to?
["$200.75", "$402.99", "$350.25"]
["200.75", "402.99", "350.25"]
["$120", "$200.75", "$350.25"]
["$350.25"]
["$200.75", "$350.25"]
What does re.findall(r"\$?(\d+\.\d{2})", prices)
evaluate to?
["$200.75", "$402.99", "$350.25"]
["200.75", "402.99", "350.25"]
["$120", "$200.75", "$350.25"]
["$350.25"]
["$200.75", "$350.25"]
Answers:
["$350.25"]
["200.75", "402.99", "350.25"]
In the first part, the string that the pattern matches is a dollar
sign ($), one or more digits (\d+), a period
(\.), two digits (\d{2}), followed by the end
of the string ($). Since the string we’re passing into
re.findall is prices, which is the
concatenation of one + ", " + two, the only option that
matches is the last price displayed, "$350.25". (If we had
not specified the match ending with the end of the string,
"$200.75" would also have been a match.)
In the second part, the beginning of the pattern is
"\$?", which means to match zero or one instance
of the dollar sign character. In most cases, this means that if there is
a dollar sign before the remainder of the pattern, it will be included
in the match, but if not, the rest of the pattern will still match.
However, the capturing group around the remainder of the pattern means
that in either case, only the remainder of the pattern after the dollar
sign is captured. (So, in this particular example, the \$?
has no effect on the output.)
The rest of the pattern is structured similarly to the previous part,
except now, the pattern does not require the end of the string after the
price, so we’re just selecting sequences of digits followed by a period
and two more digits, which is how we get our solution.
Problem 2
To prepare for the verbal component of the SAT, Yutong decides to
read research papers on data science. While reading these papers, she
notices that there are many citations interspersed that refer to other
research papers, and she’d like to read the cited papers as well.
In the papers that Yutong is reading, citations are formatted in the
verbose numeric style. An excerpt from one such paper is stored
in the string s below.
s ='''In DSC 10 [3], you learned about babypandas, a strict subsetof pandas [15][4]. It was designed [5] to provide programmingbeginners [3][91] just enough syntax to be able to performmeaningful tabular data analysis [8] without getting lost in100s of details.'''
We decide to help Yutong extract citation numbers from papers.
Consider the following four extracted lists.
For each expression below, select the list it evaluates to, or select
“None of the above.”
Problem 2.1
re.findall(r'\d+', s)
list1
list2
list3
list4
list5
None of the above
Answer: list3
This regex pattern \d+ matches one or more digits
anywhere in the string. It doesn’t concern itself with the context of
the digits, whether they are inside brackets or not. As a result, it
extracts all sequences of digits in s, including '10',
'3', '15', '4', '5',
'3', '91', '8', and
'100', which together form list3. This is
because \d+ greedily matches all contiguous digits,
capturing both the citation numbers and any other numbers present in the
text.
Problem 2.2
re.findall(r'[\d+]', s)
list1
list2
list3
list4
list5
None of the above
Answer: list5
This pattern [\d+] is slightly misleading because the
square brackets are used to define a character class, and the plus sign
inside is treated as a literal character, not as a quantifier. However,
since there are no plus signs in s, this detail does not
affect the outcome. The character class \d matches any
digit, so this pattern effectively matches individual digits throughout
the string, resulting in list5. This list contains every
single digit found in s, separated as individual string
elements.
Problem 2.3
re.findall(r'\[(\d+)\]', s)
list1
list2
list3
list4
list5
None of the above
Answer: list2
This pattern is specifically designed to match digits that are
enclosed in square brackets. The \[(\d+)\] pattern looks
for a sequence of one or more digits \d+ inside square
brackets []. The parentheses capture the digits as a group,
excluding the brackets from the result. Therefore, it extracts just the
citation numbers as they appear in s, matching
list2 exactly. This method is precise for extracting
citation numbers from a text formatted in the verbose numeric style.
Problem 2.4
re.findall(r'(\[\d+\])', s)
list1
list2
list3
list4
list5
None of the above
Answer: list4
Similar to the previous explanation but with a key difference: the
entire pattern of digits within square brackets is captured, including
the brackets themselves. The pattern \[\d+\] specifically
searches for sequences of digits surrounded by square brackets, and the
parentheses around the entire pattern ensure that the match includes the
brackets. This results in list4, which contains all the
citation markers found in s, preserving the brackets to
clearly denote them as citations.
Problem 3
In this question, you will be asked to determine which strings are
matched by various regular expression patterns when
re.search is used. For these questions, remember that
re.search(pattern, s) matches s if the pattern
can be found anywhere in s (not necessarily at the
beginning). For example,
re.search("name", "my name is pranavi") matches, while
re.search("foo", "my name is pranavi") does not.
Problem 3.1
Which of the below strings are matched by re.search
using the pattern r'a+'? Select all that apply.
"aa bb cc"
"aaa bbb ccc"
"abaaba"
"abacaba"
**Answer: Option A, B, C and D
The regex pattern r'a+' searches for any string that
contains at least one substring consisting of the character
a one or more times. Clearly all of these strings contain a
substring og the character a one or more times.
Problem 3.2
Which of the below strings are matched by re.search
using the pattern r'a+ b+'? Select all that apply.
"aa bb cc"
"aaa bbb ccc"
"abaaba"
"abacaba"
**Answer: Option A and B
The regex pattern r'a+ b+' searches for any string that
contains at least one substring consisting of the character
a one or more times followed by a space followed by the
character b one or more times. The only strings that have
this pattern are Options A and B.
Problem 3.3
Which of the below strings are matched by re.search
using the pattern r'\baa\b'?
Recall that the r at the front of the pattern string
above makes it a “raw” string; this is used so that \b is
not interpreted by Python as a special backspace character.
Select all that apply.
"aa bb cc"
"aaa bbb ccc"
"abaaba"
"abacaba"
**Answer: Option A
The regex pattern r'\b' matches for the boundary of a
word (so like the start and end of a word which could seperated by
spaces). Thus the regex pattern searches for the substring
'aa' that is its own standalone word. The only string that
has this pattern is Option A.
Problem 3.4
Which of the below strings are matched by re.search
using the pattern r'(aba){2,}'? Select all that apply.
"aa bb cc"
"aaa bbb ccc"
"abaaba"
"abacaba"
**Answer: Option C
The regex pattern r'(aba){2,}' searches the substring
consisting of aba 2 or more times. The only string that has
this pattern is Option C.
Problem 3.5
Which of the below strings are matched by re.search
using the pattern r'a..a'? Select all that apply.
"aa bb cc"
"aaa bbb ccc"
"abaaba"
"abacaba"
**Answer: Option C
The regex pattern r'a..a' searches the substring
consisting of a followed by any two characters followed by
a. The only string that has this pattern is Option C.
Problem 3.6
Which of the below strings are matched by re.search
using the pattern r'.*'? Select all that apply.
"aa bb cc"
"aaa bbb ccc"
"abaaba"
"abacaba"
**Answer: Option A, B, C and D
The regex pattern r'.*' searches the substring
consisting of any character 0 or more times. Clearly all of the strings
contain that pattern.
Problem 4
Problem 4.1
You are creating a new programming language called IDK. In this
language, all variable names must satisfy the following constraints:
They must start with Um, Umm,
Ummm, etc. That is, a capital U followed by
one or more m’s.
Following this may be any string of one or more letters. The first
letter must be capitalized.
The variable name must end with a single question mark.
Numbers or other special characters are not allowed.
Examples of valid variable names: UmmmX?,
UmTest?, UmmmmPendingQueue? Examples of
invalid variable names: ummX?, Um?,
Ummhello?, UmTest
Write a regular expression pattern string pat to
validate variable names in this new language. Your pattern should work
when re.match(pat, s) is called.
Answer: 'U(m+)[A-Z]([A-z]*)(\?)'
Starting our regular expression, it’s not too difficult to see that
we need a 'U' followed by (m+) which will
match with a singular capital 'U' followed by at least one
lowercase 'm'. Next it is required that we follow that up
with any string of letters, where the first letter is capitalized. we do
this with '[A-Z]([A-z]*)', where '[A-Z]' will
match with any capital letter and '([A-z]*)' will match
with lowercase and uppercase letters 0 or more times. Finally we end the
regex with '\?' which matches with a question mark.
Problem 4.2
Which of the following strings will be matched by the regex pattern
\$\s*\d{1,3}(\.\d{2})?? Note that it should match the
complete string given. Mark all that apply.
$ 100
$10.12
$1340.89
$1456.8
$478.23
$.99
Answer: Option A, Option B and Option E
Let’s dissect what the regex in the question actually means. First,
the '\$' simply matches with any question mark. Next,
'\s*' matches with whitespace characters 0 or more times,
and '\d{1,3}' will match with any digits 1-3 times
inclusive. Finally, '(\.\d{2})?' will match with any
expression consisting of a period and any two digits following that
period 0 or 1 times (due to the '?' mark). With those rules
in mind, it’s not too difficult to check that Options A, B and E
work.
Options C, D and F don’t work because none of those expressions have
1-3 digits before the period.
Problem 4.3
“borough”, “brough”, and “burgh” are all common suffixes among
English towns. Write a single regular expression pattern string
pat that will match any town name ending with one of these
suffixes. Your pattern should work when re.match(pat, s) is
called.
Answer: '(.*)((borough$)|(brough$)|(burgh$))'
We will assume that the question wants us to create a regex that
matches with any string that ends with the strings described in the
problem. First, '(.*)' will match with anything 0 or more
times at the start of the expression. Then
'((borough$)|(brough$)|(burgh$))' will match with any of
the described strings in the problem , since '$' indicates
the end of string and '|' is just or in
regex.
Problem 5
You want to use regular expressions to extract out the number of
ounces from the 5 product names below.
Index
Product Name
Expected Output
0
Adult Dog Food 18-Count, 3.5 oz Pouches
3.5
1
Gardetto’s Snack Mix, 1.75 Ounce
1.75
2
Colgate Whitening Toothpaste, 3 oz Tube
3
3
Adult Dog Food, 13.2 oz. Cans 24 Pack
13.2
4
Keratin Hair Spray 2!6 oz
6
The names are stored in a pandas Series called names.
For each snippet below, select the indexes for all the product names
that will not be matched correctly.
Problem 5.1
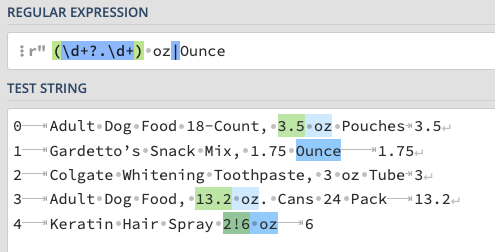
For the snippet below, which indexes correspond to products that will
not be matched correctly?
regex =r'([\d.]+) oz'names.str.findall(regex)
0
1
2
3
4
All names will be matched correctly.
Answer: Only product 1 will not be
matched; the pattern only looks for “oz” so the “Ounce” is not
identified. See this Regex101
link for an illustration.
Problem 5.2
For the snippet below, which indexes correspond to products that will
not be matched correctly?
Answer: 1, 2, and 4 are either not matched or done
so incorrectly. This pattern matches either numbers+any
character+numbers+[a space]+“oz” OR “Ounce”. However it fails in the
following ways:
For index 1, the pattern matches too little: only “Ounce” when it
should match “1.75 Ounce”.
For index 2, “3 oz” is missed entirely, as the number is a single
digit.
For index 4, the pattern matches too much: “2!6 oz” when it should
match of “6 oz”.
See this Regex101 link
for an interactive illustration.
Neeru wants to work with the 'time' column in
bus, but the times aren’t consistently formatted. He writes
the following code:
import redef convert(y1, y2, y3):returnint(y1), int(y2) if y2 else0, y3def parse(x):# Fill me inbus['time'].apply(parse)
Neeru wants the last line of his code to output a Series containing
tuples with parsed information from the 'time' column. Each
tuple should have three elements: the hour, minute, and either
'am' or 'pm' for each time. For example, the
first two values in the 'time' column are
'12pm' and '1:15pm', so the first two tuples
in the Series should be: (12, 0, 'pm') and
(1, 15, 'pm').
Select all the correct implementations of the
function parse. Assume that each value in the
'time' column starts with one or two digits for the hour,
followed by an optional colon and an optional two digits for the minute,
followed by either “am” or “pm”.
Hint: Calling .groups() on a regular expression
match object returns the groups of the match as a tuple. For nested
groups, the outermost group is returned first. For example:
def parse(x): res = x[:-2].split(':')return convert(res[0], res[1] iflen(res) ==2else0, x[-2:])
Option B:
def parse(x): res = re.match(r'(\d+):(\d+)([apm]{2})', x).groups()return convert(res[0], res[1], res[2])
Option C:
def parse(x): res = re.match(r'(\d+)(:(\d+))?(am|pm)', x).groups()return convert(res[0], res[2], res[3])
Option D:
def parse(x): res = re.match(r'(.+(.{3})?)(..)', x).groups()return convert(res[0], res[1], res[2])
Answer: Options A and C
Option A: First, we grab everything but 'am' /
'pm' with x[:-2]. Then splitting on
':' means that values such as '1:15' become a
list like ['1', '15'], while single numbers such as
'12' become a list like ['12']. We then pass
in the hour value, the minute value or 0 if there is none,
and then the 'am' / 'pm' value by grabbing
just the last two indices of x.
Option B: We use regex to define groups from x and
return a list of those groups using .groups(). The regex
matches to any number of integers '(\d+)' as the first
group, then a colon ':', another group of any number of
integers '(\d+)', then a final group that matches exactly
twice to characters from “apm”, which can be “am” or “pm” with
'([apm]{2})'. The problem with this solution is that while
it does correctly match to input such as '1:15pm', it would
not match to '12pm' because there is no ':'
character.
Option C: We use regex to define groups from x and
return a list of those groups using .groups(). The regex
matches to any number of integers '(\d+)' as the first
group, then looks for a colon ':' as the second group, and
matches another group to any number of integers following it with
'(\d+)'. The '?' character makes the previous
matches optional, so if there is no ':' followed by
integers then it will return None for groups 2 and 3 and
still match the rest of the string. Finally, it matches one last group
that is any two characters after the previous groups. This solution
works because the full regex matches the format '1:15pm',
while the '?' checks so if there is no ':' it
can still match something formatted like '12pm'. It also
passes in the group indices 0, 2, and 3 because group 1 will just be
':digits' or None, so we want to skip it. (By
digits, we mean the digits that are after the colon, if
any, like :45.)
Option D: We use regex to define groups from x and
return a list of those groups using .groups(). The regex
matches any character unlimited times with '.+' as the
first group, then has another group that takes 3 of any character after
the first group from '(.{3})?, and this group is optional
because of the ending '?'. Finally, the last two characters
are the last group '(..)'. This solution does not work
because while the intention is that '.+' grabs the hour and
'(.{3})?' grabs the colon and minutes if present, the
'.+' just grabs everything because the '+'
matches unlimited times. Therefore, '1:15pm' returns the
groups ['1:15', None, 'pm'], which doesn’t work with our
convert function.
Problem 7
Problem 7.1
Each Spotify charts webpage is specific to a particular country (as
different countries have different music tastes). Embedded in each
charts page is a “datestring", that describes:
the number of songs on the page,
the country, and
the date.
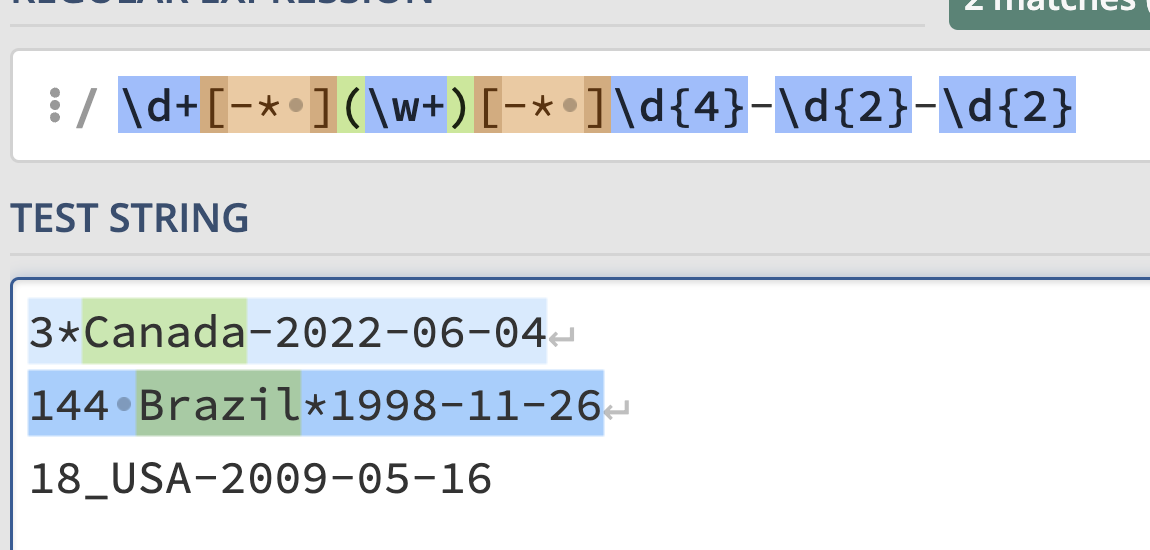
For instance, "3*Canada-2022-06-04" is a datestring
stating that the page contains the top 3 songs in Canada on June 4th,
2022. A valid datestring contains a number, a country name, a year, a
month, and a day, such that:
the number, country name, and year are each separated by a single
dash ("-"), asterisk ("*"), or space
(" ").
the year, month, and day are each separated by a single dash
("-") only
Below, assign exp to a regular expression that
extracts country names from valid datestrings. If the
datestring does not follow the above format, it should not extract
anything. Example behavior is given below.
Click this link to
interact with the solution on regex101.
Problem 7.2
Consider the following regular expression.
r"^\w{2,5}.\d*\/[^A-Z5]{1,}"
Select all strings below that contain any
match with the regular expression above.
"billy4/Za"
"billy4/za"
"DAI_s2154/pacific"
"daisy/ZZZZZ"
"bi_/_lly98"
"!@__!14/atlantic"
Answer: Option B, Option C, and Option E
Let’s first dissect the regular expression into manageable
groups:
"^" matches the regex to its right at the start of a
given string
"\w{2,5}" matches alphanumeric characters (a-Z, 0-9 and
_) 2 to 5 times inclusively. (Note the that it does indeed match with
the underscore)
"." is a basic wildcard
"\d*" matches digits (0-9), at least 0 times
"\/" matches the "/" character
"[^A-Z5]{1,}" matches any character that isn’t (A-Z or
5) at least once.
Thus using these rules, we can verify that Options B, C and E are
matches.
Problem 7.3
Consider the following string and regular expressions:
song_str = "doja cat you right"
exp_1 = r"\b\w+\b" # \b stands for word boundary
exp_2 = r" \w+"
exp_3 = r" \w+ "
What does len(re.findall(exp_1, song_str)) evaluate
to?
What does len(re.findall(exp_2, song_str)) evaluate
to?
What does len(re.findall(exp_3, song_str)) evaluate
to?
Answer: See below
"\b" matches “word boundaries", which are any
locations that separate words. As such, there are 4 matches —
["doja", "cat", "you", "right"]. Thus the answer is
4.
The 3 matches are [" cat", " you", " right"]. Thus
the answer is 3.
This was quite tricky! The key is remembering that
re.findall only finds non-overlapping
matches (if you look at the solutions to the above two parts,
none of the matches overlapped). Reading from left to right, there is
only a single non-overlapping match: "cat". Sure,
" you " also matches the pattern, but since the space after
"cat" was already “found" by re.findall, it
cannot be included in any future matches. Thus the answer is 1.
Problem 8
Nishant decides to look at reviews for the Catamaran Resort Hotel and
Spa. TripAdvisor has 96 reviews for the hotel; of those 96, Nishant’s
favorite review was:
"close to the beach but far from the beach beach"
Problem 8.1
What is the TF of "beach" in Nishant’s favorite review?
Give your answer as a simplified fraction.
Answer:\frac{3}{10}
The answer is simply the proportion of words in the sentence that are
the word "beach". There are 10 words in the sentence, 3 of
which are "beach".
Problem 8.2
The TF-IDF of "beach" in Nishant’s favorite review is
\frac{9}{10}, when using a base-2
logarithm to compute the IDF. How many of the reviews on TripAdvisor for
this hotel contain the term "beach"?
3
6
8
12
16
24
32
Answer: 12
The TF-IDF is the product of the TF and IDF terms. So if the TF-IDF
of this document is \frac{9}{10}, and
the TF is \frac{3}{10}, as established
in the last part, the IDF of the term "beach" is 3. The IDF
for a word is the log of the inverse of the proportion of documents in
which the word appears. So, since we know there are 96 total
documents.
The DataFrame below contains a corpus of four song titles, labeled
from 0 to 3.
Problem 9.1
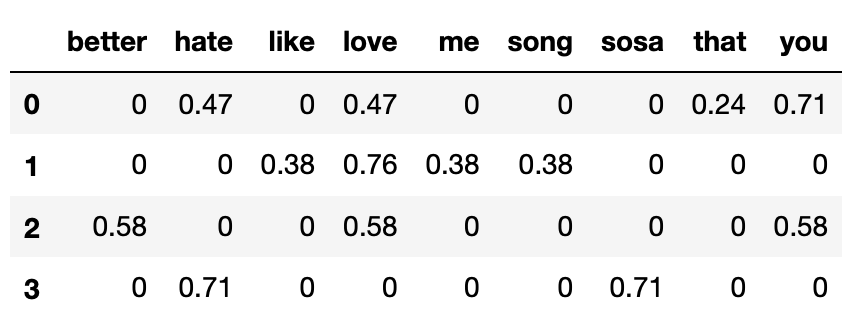
What is the TF-IDF of the word "hate" in Song 0’s title?
Use base 2 in your logarithm, and give your answer as a simplified
fraction.
Answer: \frac{1}{6}
There are 12 words in Song 0’s title, and 2 of them are
"hate", so the term frequency of "hate" in
Song 0’s title is \frac{2}{12} =
\frac{1}{6}.
There are 4 documents total, and 2 of them contain
"hate" (Song 0’s title and Song 3’s title), so the inverse
document frequency of "hate" in the corpus is \log_2 \left( \frac{4}{2} \right) = \log_2 (2) =
1.
Then, the TF-IDF of "hate" in Song 0’s title is
\text{TF-IDF} = \frac{1}{6} \cdot 1 =
\frac{1}{6}
Problem 9.2
Which word in Song 0’s title has the highest TF-IDF?
"i"
"hate"
"you"
"love"
"that"
Two or more words are tied for the highest TF-IDF in Song 0’s
title
Answer: Option A: "i"
It was not necessary to compute the TF-IDFs of all words in Song 0’s
title to determine the answer. \text{tfidf}(t,
d) is high when t occurs often
in d but rarely overall. That is the
case with "i" — it is the most common word in Song 0’s
title (with 4 appearances), but it does not appear in any other
document. As such, it must be the word with the highest TF-IDF in Song
0’s title.
Problem 9.3
Let \text{tfidf}(t, d) be the TF-IDF
of term t in document d, and let \text{bow}(t, d) be the number of occurrences
of term t in document d.
Select all correct answers below.
If \text{tfidf}(t, d) = 0, then
\text{bow}(t, d) = 0.
If \text{bow}(t, d) = 0, then \text{tfidf}(t, d) = 0.
Neither of the above statements are necessarily true.
Answer: Option B
Recall that \text{tfidf}(t, d) =
\text{tf}(t, d) \cdot \text{idf}(t), and note that \text{bow}(t, d) is the numerator of \text{tf}(t, d). Thus, \text{tfidf}(t, d) is 0 is if either \text{bow}(t, d) = 0 or \text{idf}(t) = 0.
So, if \text{bow}(t, d) = 0, (which
happens with term t is not in document
d) then \text{tf}(t, d) = 0 and thus \text{tfidf}(t, d) = 0, so the second option
is true. However, if \text{tfidf}(t, d) =
0, it could be the case that \text{bow}(t, d) > 0 and \text{idf}(t) = 0 (which happens when term
t is in every document), so the first
option is not necessarily true.
Problem 9.4
Below, we’ve encoded the corpus from the previous page using the
bag-of-words model.
Note that in the above DataFrame, each row has been normalized to
have a length of 1 (i.e. |\vec{v}| = 1
for all four row vectors).
Which song’s title has the highest cosine similarity with Song 0’s
title?
Song 1
Song 2
Song 3
Answer: Option B: Song 2
Recall, the cosine similarity between two vectors \vec{a}, \vec{b} is computed as
We are told that each row vector is already normalized to have a
length of 1, so to compute the similarity between two songs’ titles, we
can compute dot products directly.
Song 0 and Song 1: 0.47 \cdot
0.76
Song 0 and Song 2: 0.47 \cdot 0.58 +
0.71 \cdot 0.58
Song 0 and Song 3: 0.47 \cdot
0.71
Without using a calculator (which students did not have access to
during the exam), it is clear that the dot product between Song 0’s
title and Song 2’s title is the highest, hence Song 2’s title is the
most similar to Song 0’s.
Problem 10
Problem 10.1
Consider the following four sentences:
“this is one”
“this is two”
“this is the third”
“and this is the fourth”
Suppose these sentences are encoded into a “bag of words” feature
representation. The result is a DataFrame with four rows (one for each
sentence). How many columns are in this DataFrame? Your answer should be
in the form of a number.
Answer: 8
Recall that bag of word creates a new column for each unique word.
Thus the problem boils down to “how many unique words are there in the
following four sentences”, which we count 8: “this”, “is”, “one”, “two”,
“the”, “third”, “and”, “fourth”.
Problem 10.2
Again consider the same four sentences shown above.
What is the TF-IDF score for the word “this” in the first sentence?
Use base-2 logarithm.
Your answer should be in the form of a number.
Answer: 0
Recall that TF is calculated as the number of terms that appear in
that sentence divided by the total number of terms in the sentence. In
this case the TF value of “this” in the first sentence is \frac{1}{3}.
IDF is calculated as the log of the number of sentences divided by
the number of sentences in which that term appears in. In this case, the
IDF value of “this” in the first sentence is \log_{2}(\frac{4}{4}) = 0.
Thus the TF-IDF is just \frac{1}{3} * 0 =
0
Problem 10.3
Again consider the same four sentences shown above.
What is the TF-IDF score for the word “and” in the last sentence? Use
base-2 logarithm.
Your answer should be in the form of a number.
Answer: 0.4
Recall that TF is calculated as the number of terms that appear in
that sentence divided by the total number of terms in the sentence. In
this case the TF value of “and” in the last sentence is \frac{1}{5}.
IDF is calculated as the log of the number of sentences divided by
the number of sentences in which that term appears in. In this case, the
IDF value of “and” in the last sentence is \log_{2}(\frac{4}{1}) = 2.
Thus the TF-IDF is just \frac{1}{5} * 2 =
0.4
Problem 11
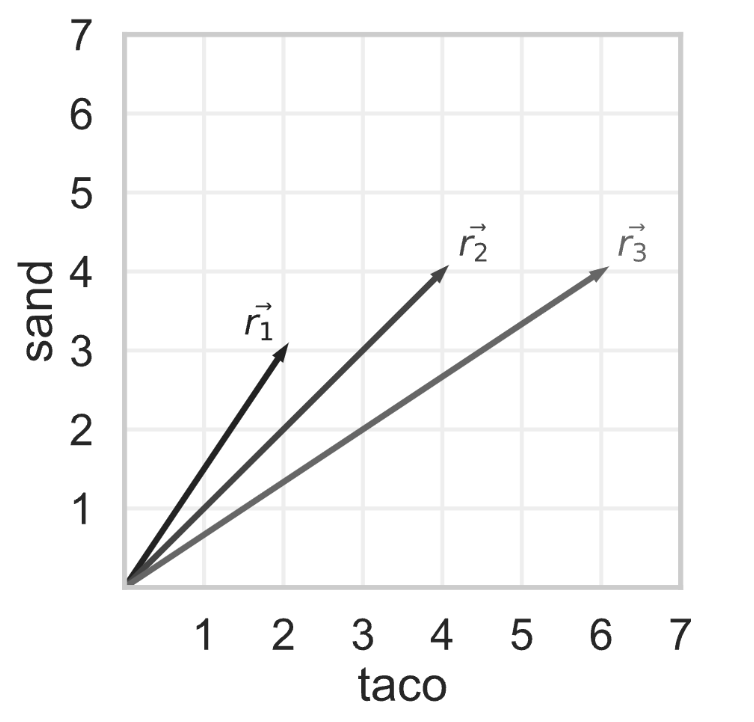
Tahseen decides to look at reviews for the same hotel, but he
modifies them so that the only terms they contain are
"taco" and "sand". The bag-of-words
representations of three reviews are shown as vectors below.
Using cosine similarity to measure similarity, which pair of reviews
are the most similar? If there are multiple pairs of reviews that are
most similar, select them all.
\vec{r}_1 and \vec{r}_2
\vec{r}_1 and \vec{r}_3
\vec{r}_2 and \vec{r}_3
Answer:\vec{r}_1
and \vec{r}_2, and\vec{r}_2 and \vec{r}_3
The cosine similarity of two vectors \vec{a} and \vec{b} is \frac{\vec{a} \cdot \vec{b}}{||\vec{a}|| \cdot
||\vec{b}||}.
The cosine similarity of \vec{r}_1
and \vec{r}_2 is: \frac{2 \cdot 4 + 3 \cdot 4}{\sqrt{13} \cdot
\sqrt{32}} = \frac{20}{4 \cdot \sqrt{26}} =
\frac{5}{\sqrt{26}}
The cosine similarity of \vec{r}_1
and \vec{r}_3 is: \frac{2 \cdot 6 + 3 \cdot 4}{\sqrt{13} \cdot
\sqrt{52}} = \frac{24}{26} = \frac{12}{13}
The cosine similarity of \vec{r}_2
and \vec{r}_3 is: \frac{4 \cdot 6 + 4 \cdot 4}{\sqrt{32} \cdot
\sqrt{52}} = \frac{40}{8 \cdot \sqrt{26}} =
\frac{5}{\sqrt{26}}
\frac{12}{13} \approx 0.9231 and
\frac{5}{\sqrt{26}} \approx 0.9806.
Since larger cosine similarities mean more similar
vectors, our answer is vector pairs \vec{r}_1, \vec{r}_2 AND \vec{r}_2, \vec{r}_3.
Note that we could’ve answered the question without finding the
cosine similarity between \vec{r}_1 and
\vec{r}_3. Remember, the cosine
similarity between two vectors is the cosine of the
angle between the two vectors.
The angle between \vec{r}_1 and
\vec{r}_3 is clearly bigger than the
angle between \vec{r}_1 and \vec{r}_2, because \vec{r}_2 is in between \vec{r}_1 and \vec{r}_3, so we can rule out \vec{r}_1 and \vec{r}_3.
The question then boils down to comparing the angle between \vec{r}_1, \vec{r}_2 and the angle between
\vec{r}_2, \vec{r}_3. We can compute the cosine
similarities of both pairs, as we did above. But, there’s a slightly
easier way!
Specifically, note that \vec{r}_3 =
\begin{bmatrix} 6 \\ 4 \end{bmatrix} = 2 \begin{bmatrix} 3 \\ 2
\end{bmatrix}, i.e. it is a scalar multiple of \begin{bmatrix} 3 \\ 2 \end{bmatrix}, meaning
\vec{r}_3 points in the same direction
as \begin{bmatrix} 3 \\ 2
\end{bmatrix}, just is twice the length. This means that the
angle between \vec{r}_2 and \vec{r}_3 is the same as the angle between
\vec{r}_2 and \begin{bmatrix} 3 \\ 2 \end{bmatrix} (and
remember, if two pairs of vectors have the same angle between them, they
have the same cosine similarity).
Why does that matter? Because, now we’re comparing the cosine
similarity between: \vec{r}_1 =
\begin{bmatrix} 2 \\ 3 \end{bmatrix}, \vec{r}_2 = \begin{bmatrix} 4
\\ 4 \end{bmatrix} \\ \\ \text{ and } \\ \\ \vec{r_2} = \begin{bmatrix}
4 \\ 4 \end{bmatrix}, \frac{1}{2}\vec{r}_3 = \begin{bmatrix} 3 \\ 2
\end{bmatrix}
Because of symmetry (work this out yourself!), the two pairs of
vectors have the same cosine similarity, and thus the same angle!
Problem 12
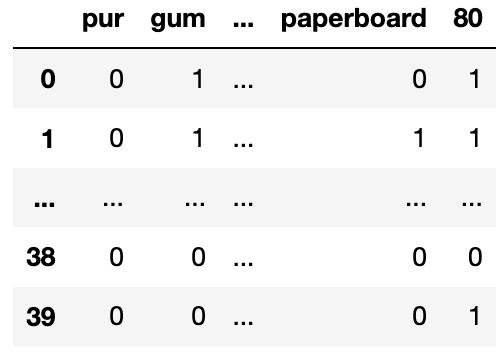
You create a table called gums that only contains the
chewing gum purchases of df, then you create a bag-of-words
matrix called bow from the name column of
gums. The bow matrix is stored as a DataFrame
shown below:
For each question below, write your answer as an unsimplified math
expression (no need to simplify fractions or logarithms) in the space
provided, or write “Need more information” if there is not enough
information provided to answer the question.
Problem 12.1
What is the TF-IDF for the word “pur” in document 0?
Answer: 0
First, it’s worth discussing what information we have.
bow_df.sum(axis=0) computes the sum of each
column of bow_df. Each column of
bow_df refers to a specific word, so the sum of a column in
bow_df tells us the number of occurrences of a particular
word across the entire corpus (all documents).
bow_df.sum(axis=1) computes the sum of each
row of bow_df. Each row of
bow_df refers to a specific document, so the sum of a row
in bow_df tells us the number of words in a
particular document.
bow_df.loc[0, 'pur'] being 0 tells us that
the word "pur" appears 0 times in document 0.
(bow_df["paperboard"] > 0).sum() being
20 means that there are 20 documents that contain the word
"paperboard".
bow_df["gum"].sum() being 41 means that
"gum" appears 41 times across all documents.
Now, back to the subpart at hand. The TF-IDF of “pur” in document 0
is 0, because bullet point 3 above tells us that “pur”
doesn’t occur at all in document 0. This means that the term frequency
of “pur” in document 0 is 0, which means the TF-IDF (which is the
product of the term frequency and inverse document frequency) of “pur”
in document 0 is also 0, because 0 multiplied by the IDF of “pur” must
be 0.
Problem 12.2
What is the TF-IDF for the word “gum” in document 0?
Answer: Need more information
Let’s try and compute the TF-IDF of “gum” in document 0. The formula
is as follows:
= \frac{\# \text{ of words in document 0 equal to gum}}{\# \text{ of
words in document 0}} \cdot \log \left( \frac{\text{ total \# of
documents}}{\text{total \# of documents containing gum}} \right)
We don’t know the number of documents containing “gum” – all we know
(from bullet point 5 in the previous solution) is that “gum” appears 41
times across all documents, but we don’t know how many unique documents
contain “gum”. So, we need more information.
Problem 12.3
What is the TF-IDF for the word “paperboard” in document 1?
Answer:\frac{1}{22}
Let’s try and compute the TF-IDF of “paperboard” in document 1. The
formula is as follows (assuming a base-2 logarithm):
= \frac{\text{\# of words in document 1 equal to
"paperboard"}}{\text{\# of words in document 1}} \cdot \log
\left( \frac{\text{total \# of documents}}{\text{total \# of documents
containing "paperboard"}} \right)
Suppose we create a TF-IDF matrix, in which there is one row for each
sentence and one column for each unique word. The value in row i and column j is the TF-IDF of word j in sentence i. Note that since there are 5 sentences and
5 unique words across all sentences, the TF-IDF matrix has 25 total
values.
Is there a column in the TF-IDF matrix in which all values are 0?
In the context of TF-IDF, if a word appears in every sentence, its
inverse document frequency (IDF) would be \log(\frac{5}{5}) = 0. Since a word’s TF-IDF
in a document is its TF (term frequency) in that document multiplied by
its IDF, if the word’s IDF is 0, it’s TF-IDF is also 0. Since “the”
appears in all five sentences, its IDF is zero, leading to a column of
zeros in the TF-IDF matrix for “the”.
Problem 13.2
In which of the following sentences is “college” the word with the
highest TF-IDF?
Sentence 1
Sentence 2
Sentence 3
Sentence 4
Sentence 5
Answer: Sentence 4
Remember, the IDF of a word is the same for all documents, since
\text{idf}(t) = \log \left( \frac{\text{number
of documents}}{\text{number of documents containing } t} \right).
This means that the sentence where “college” is the word with the
highest TF-IDF is the same as the sentence where “college” is the word
with the highest TF, or term frequency. Sentence 4 is the only sentence
where “college” appears twice; in all other sentences, “college” appears
at most once. (Since all of these sentences have the same length, we
know that if “college” appears more times in Sentence 4 than it does in
other sentences, then “college”’s term frequency in Sentence 4, \frac{2}{5}, is also larger than in any other
sentence.) As such, the answer is Sentence 4.
Problem 13.3
As an alternative to TF-IDF, Suraj proposes the DF-ITF, or “document
frequency-inverse term frequency”. The DF-ITF of term t in document d is defined below:
\text{df-itf}(t, d) = \frac{\text{\# of
documents in which $t$ appears}}{\text{total \# of documents}} \cdot
\log \left( \frac{\text{total \# of words in $d$}}{\text{\# of
occurrences of $t$ in $d$}} \right)
Fill in the blank: The term t in
document d that best summarizes
document d is the term with ____.
the largest DF-ITF in document d
the smallest DF-ITF in document d
Answer: the smallest DF-IDF in document d
The key idea behind TF-IDF, as we learned in class, is that t is a good summary of d if t
occurs commonly in d but rarely across
all documents.
When t occurs often in d, then \frac{\text{\# of occurrences of $t$ in
$d$}}{\text{total \# of words in $d$}} is large, which means
\frac{\text{total \# of words in
$d$}}{\text{\# of occurrences of $t$ in $d$}} and hence \log \left( \frac{\text{total \# of words in
$d$}}{\text{\# of occurrences of $t$ in $d$}} \right) is
small.
Similarly, if t is rare across all
documents, then \frac{\text{\# of documents in
which $t$ appears}}{\text{total \# of documents}} is small.
Putting the above two pieces together, we have that \text{df-itf}(t, d) is small when t occurs commonly in d but rarely overall, which means that the
term t that best summarizes d is the term with the smallest DF-IDF in
d.
Problem 14
Consider the following corpus:
Document number
Content
1
yesterday rainy today sunny
2
yesterday sunny today sunny
3
today rainy yesterday today
4
yesterday yesterday today today
Problem 14.1
Using a bag-of-words representation, which two documents have the
largest dot product? Show your work, then write your final answer in the
blanks below.
Documents ____ and ____
Answer: Documents 3 and 4
The bag-of-words representation for the documents is:
Document number
yesterday
rainy
today
sunny
1
1
1
1
1
2
1
0
1
2
3
1
1
2
0
4
2
0
2
0
The dot product between documents 3
and 4 is 6, which is the highest among all pairs of
documents.
Problem 14.2
Using a bag-of-words representation, what is the cosine similarity
between documents 2 and 3? Show your work below, then write your
final answer in the blank below.
Answer: \frac{1}{2}
The dot product between documents 2
and 3 is: 1
+ 0 + 2 + 0 = 3 The magnitude of document 2 is equal to document 3 and is: \sqrt{1^2 + 0 ^2 + 1^2 + 2^2} = \sqrt{6} So,
the cosine similarity is \frac{3}{\sqrt{6}\times\sqrt{6}} =
\frac{1}{2}
Problem 14.3
Which words have a TF-IDF score 0
for all four documents? Assume that we use base-2 logarithms.
Select all the words that apply.
where \text{tf}(d, t), the term
frequency of term t in document d, is the proportion of terms in d that are equal to t, and \text{idf}(t) = \log \left( \frac{\text{number of
documents}}{\text{number of documents containing $t$}}
\right).
In order for \text{tf-idf}(t, d) to
be 0, either t must not be in document
d (meaning \text{tf}(t, d) = 0), or t is in every document (meaning \text{idf}(t) = \log(\frac{n}{n}) = \log(1) =
0). In this case, we’re looking for words that have a \text{tf-idf} of 0 across all documents,
which means we’re looking for words that have a \text{idf}(t) of 0, meaning they’re in every
document. The words that are in every document are yesterday and
today.